How to create a broken UTF-8 CSV
Create a broken utf8 CSV for use in your unit tests


Context
I recently worked on a solution for this error:
'utf-8' codec can't decode byte 0x96 in position 19: invalid start byte
This happened because we switched to a new function: pandas.read_csv and the default behavior on error is to throw a UnicodeDecodeError exception. For us the fix was easy, it is just a matter of setting encoding_errors="ignore" to replicate the previous behavior.
What wasn't as easy was creating a broken file to run our tests against. There's a lot of information online for how to fix this error, but not a lot on how to replicate it. I do not have access to the data that caused the issue and I do not know how it was created (although I suspect it was exported from Excel on Windows).
Solution
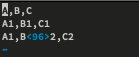
This Python script will create a csv file and insert the binary 0x96 character we need.
# Open normally and write the first section
with open('broken.csv', 'w') as f:
f.write('A,B,C\n')
f.write('A1,B1,C1\n')
f.write('A2,B')
# Open again in binary append
with open('broken.csv', 'ab') as f:
f.write(b"\x96")
# Open one final time to append a few more characters
with open('broken.csv', 'a') as f:
f.write('2,C2')
Validate
Now that I have this file I can assert on 2 things in my unit tests:
- That the default function throws (check the csv is actually broken).
- That the function with
ignorereads the contents as expected.
There are 2 functions on Linux that helped validate the 'broken' nature of this file.
$ iconv -f utf8 broken.csv -t utf8 -o /dev/null
iconv: illegal input sequence at position 19and
$ file -bi broken.csv
text/plain; charset=unknown-8bit


